
How can Europe make AI safe and reliable?
SaferAI’s recent position paper made a case for European Investment in High-Risk, High-Reward AI Reliability Research. The case was economic, strategic, and institutional: Europe’s economy is especially strong in safety-critical sectors, current AI systems lack the ex-ante guarantees those sectors require, and private frontier AI companies are structurally disincentivized to supply this research at the necessary scale. We also argued that, as AI labs race toward Artificial General Intelligence (AGI), the risks from this technology are too large to accept safety methods that cannot provide meaningful guarantees.
This blog post asks a follow-up question: What technologies could the EU fund to make AI reliability research a reality?
Through the Coalition for AI Assurance (CAIA), chaired by Yoshua Bengio, David Dalrymple, and Luke Ong, SaferAI convenes leading researchers working on this problem. Drawing on their work, we map four possible approaches to frontier AI assurance and the open questions each would need to solve to be successful.
The four paths to AI assurance
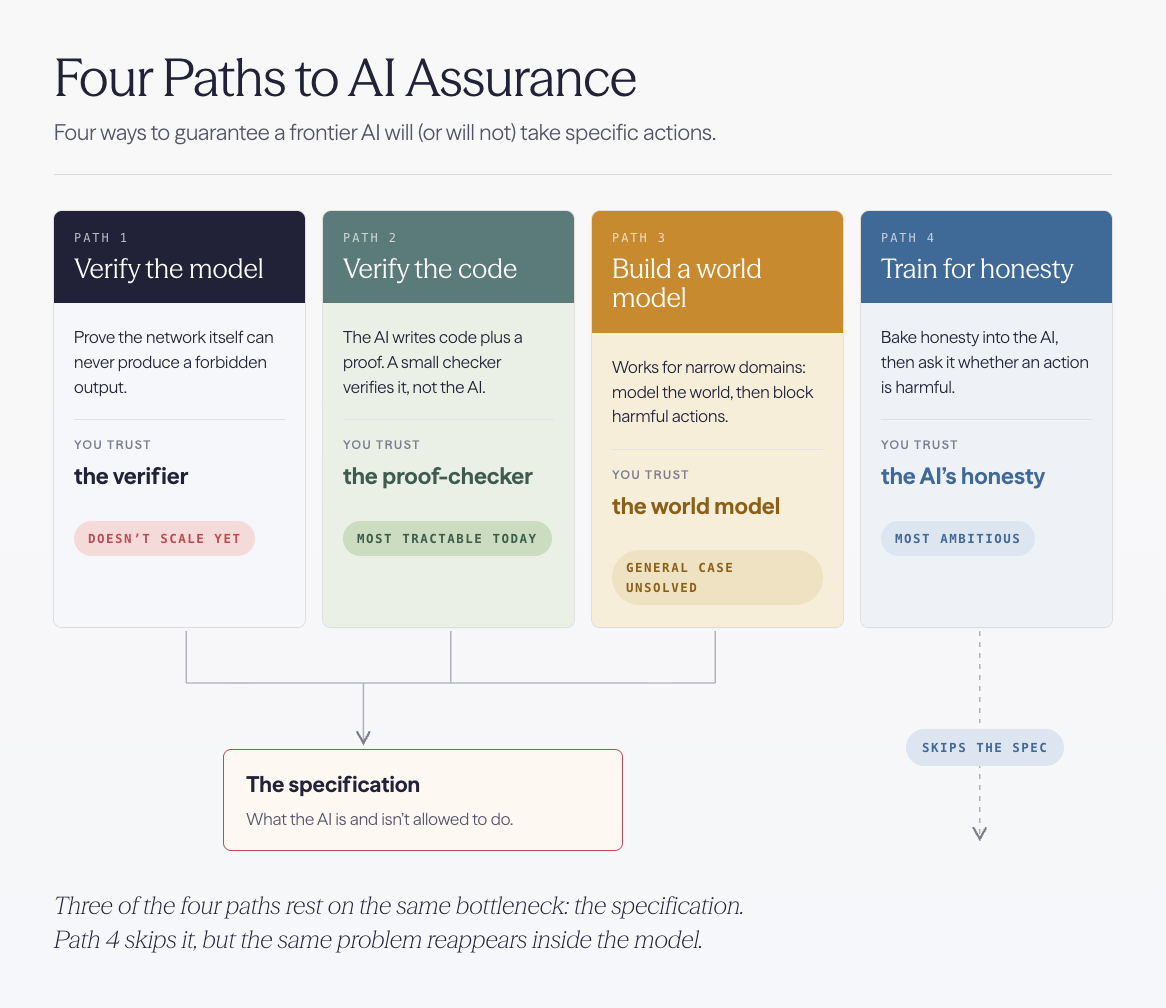
In our research on which AI assurance bets Europe could fund, we identify four broad research directions that could lead to reliable and safe AI:
- Verify the model itself. Prove mathematical safety properties about the neural network directly, pre-deployment.
- Verify the code the AI generates against a specification. Let the AI generate code plus a proof, and trust the checker rather than the AI. This approach is sometimes called Secure Program Synthesis (SPS) or vericoding.
- Build a model of the world and check the AI against it. Construct a symbolic model of a complex system and verify AI actions against it.
- Train the AI to be honest. Instead of building a separate world model, bake honesty into the AI itself and use it to generate models on the fly.
Each approach is technically deep, and a full treatment is out of scope; the sections that follow walk the open questions inside each.
The specification problem
Before we go through the four paths one by one, it is worth zooming in on a problem that underlies most of them. To guarantee the safety of a technology, one has to define what “harm” is and prove that the technology will never cross past the harm threshold. Three of the four paths above (Paths 1, 2, and 3) rely on the same bottleneck: someone has to write down, precisely, what the AI is and is not allowed to do. This is a specification, or “spec”. A specification is a safety property written precisely enough that a machine can check it. For example, aircraft software comes with rules like “during a go-around maneuver, the aircraft must maintain a positive climb rate.” This is key, because the proof is only ever as strong as the rules it is proving against. Verify the wrong thing, and you have verified nothing. Path 4 deliberately skips this step, something we explore in more depth in its own section.
Specification is a hard problem. Rules usually only exist in natural language, and translating them into formal logic at an industrial scale is a research problem in its own right. Recently, researchers have started experimenting with using AI for this translation. However, this comes with its own problems. Current benchmarks show that LLMs are decently good at accurately translating requirements into formal specs, but they are far worse at making the specification sound and complete – meaning they usually do not actually capture all of the safety-relevant properties. The libcrux disclosure (February 2026) found four bugs inside formally verified cryptographic code: the proofs were right, the specs missed cases. Verified, on the wrong claim.
Having a precise specification is the clearest bottleneck for getting good AI assurance, as all other aspects of assurance rest on the spec being sound and complete.

Path 1: Direct neural network verification
The most direct approach to AI assurance is to take the neural network itself and prove mathematically that it cannot produce a forbidden output. This works for small networks and is routinely used today for narrow safety-critical subsystems (Airbus, Paris metro).
However, the problem is scale. Verifying a neural network’s behavior across all inputs is NP-complete: the computational work grows exponentially with the size of the network, meaning adding a few neurons can multiply it a millionfold. A decade of intensive work has barely moved the ceiling above tens of millions of parameters, and current frontier models are in the trillions of parameters. We do not see this path scaling to frontier AI. We mention it because it is what most people imagine “formal verification of AI” means and to be explicit that the other three paths are responses to its insufficiency.
Path 2: Secure programme synthesis
The core idea behind secure program synthesis (SPS) is to shift what needs to be trusted. When an AI writes code today, one has to trust the AI itself or go through the code line by line and make sure there are no vulnerabilities.
In SPS the AI writes the code as well as a mathematical proof ensuring the code does what was specified; then, a small separate program, the proof checker, is run to verify the proof. If the AI’s proof is wrong, the checker rejects it. If it goes through, it means the program is guaranteed to comply with the specification (as discussed in the previous section) with mathematical certainty.
Initially, this approach might appear more limited because it focuses on verifying code. However, it is arguably becoming increasingly promising. As AI-generated code continues to grow each year, it is likely introducing many new software vulnerabilities every day. In addition, AI models like Claude Mythos are becoming worryingly capable at cyber-offense, and proving that software is safe would be a welcome addition to cybersecurity efforts.
To date, full formal verification of this kind has remained confined to niche domains such as operating system kernels, because the cost of writing proofs manually is prohibitively expensive. The bet with SPS is that AI removes the cost barrier and makes this kind of verification tractable for ordinary software.
As Dougherty et al. emphasize, a key caveat is that programs accompanied by formal proofs do not automatically guarantee safety. As explained above, a proof can be entirely correct, yet it can still establish verification with a flawed specification.
Therefore, the central challenge and important research direction for SPS is not improving theorem provers but addressing the specification problem. Some potential paths include work on interactive spec elicitation, which would allow a domain expert to articulate requirements in natural language without learning proof assistant languages. NASA’s FRET and the European Mu-FRET project represent early examples of this approach. Another promising path is adversarial specification review, based on the idea of AI safety via debate, where one AI agent writes the spec and another searches for gaps and ambiguities before verification begins.
Path 3: Symbolic world models
Path 3 approaches the specification problem from a different angle. Instead of expressing rules based on system requirements in formal logic (which is hard even for well-defined domains like software), it seeks to build a symbolic model of how a slice of the world actually works. Every action proposed by the AI system is then evaluated against that model. If the model predicts that the action would cause harm, the action is blocked. In effect, the world model becomes the specification; it is the standard against which every action must be proven against.
The motivating logic is that for many tasks, harm is easier to define and describe by reference to physical reality than with an exhaustive set of written rules. For an AI managing a power grid, the central question is not whether its actions satisfy a formal specification, but whether they will keep the physical system stable. A sufficiently accurate model of grid dynamics could answer that question.
This idea underpins the Guaranteed Safe AI (GSAI) framing and was the original focus of the Advanced Research and Invention Agency (ARIA, UK’s “ARPA style” organization) Safeguarded AI programme before its pivot in November 2025.
The near-term applicability of this approach lies in narrow, well-defined domains such as battery dynamics, control loops, and other physical processes governed by established mathematical models. By contrast, constructing reliable and meaningful models of social, political, and economic slices of the world remains an unresolved challenge. This limitation was a reason for ARIA’s decision to narrow the program’s scope in late 2025.
The fundamental open problem is world-model completeness. Analogously to the specification problem, the guarantees provided by the system are only as strong as the model it relies on. If the model does not represent the mechanism by which an action could cause harm, the system may erroneously conclude the action is “safe,” and the action goes through.
Path 4: Honest predictors (Scientist AI)
The fourth path is structurally different from the other three. Rather than attempting to verify actions against specifications, proofs, or world models, it aims to train the AI directly to be honest about what is true and about the likely consequences of its actions. This “Scientist AI” is built to be queriable in two ways: about factual claims and about whether a proposed action would cause harm. The underlying hypothesis, as Turing Award laureate and originator of the approach Yoshua Bengio recently stated on a podcast, is that “if we can bake honesty into AI, we can get safety.”
The motivation stems from a critique of how current large language models (LLMs) are trained. During pretraining, models learn from a vast human-written corpus, inheriting factual information as well as the goals, perspectives, and rhetorical patterns of the humans who wrote it. In effect, the outcome is an answer in the voice of whatever persona the prompt was conditioned on, not the model’s direct representation of the truth, which is only learned implicitly as part of predicting human-written text. Subsequent reinforcement-learning post-training can exacerbate this. By rewarding outputs that human evaluators prefer, it encourages the model to produce answers that are agreeable/useful rather than strictly accurate, leading to phenomena like sycophancy and reward-hacking. LawZero, the non-profit founded by Bengio, aims to address this problem through two changes to the training process.
First, the training corpus is relabelled so every statement carries its source (“Newton said X in 1666” rather than just “X”.) This separates the fact that a statement was made from the question of whether the content is true. In principle, this gives the model the vocabulary to distinguish between claims and reality, enabling a query mode for users that returns the model’s own probability estimates rather than a persona’s stated belief.
Second, training is constrained so that gradient updates depend only on how well the model predicts existing data, never on the downstream consequences of its predictions. This rules out reinforcement learning and any other outcome-aware training procedure that might teach the model that its outputs can influence the world. These two training interventions have the end goal of producing a system that functions as a predictor that is honest by construction.
The pilot plan for the Scientist AI is a fine-tuned open-weights LLM, taught to differentiate between “fact mode” responses and ordinary “communicative mode” responses. The long-term aim is more ambitious: a frontier-scale Scientist AI trained from initialization under the same constraints and deployed as both a source of reliable knowledge and a safety guardrail for AI systems. Bengio has been explicit that LawZero alone cannot build the frontier-scale version. Achieving this would require a frontier-lab partner or a multi-government coalition.
The open problem for this path is that it is still unproven for now. There are currently no examples of this approach demonstrating that these training constraints can reliably produce honest AI. Although this approach benefits from its compatibility with the existing LLM paradigm and can therefore leverage the broad knowledge of LLMs, it remains uncertain in practice.
What does this mean for European Investment?
So, which of these technologies should the EU back?
Some of it is already happening. The French Institute for Research in Computer Science and Automation (INRIA) has been working on formal methods for decades and has announced a collaboration with Mitsubishi on SPS for manufacturing. At TU Graz, researchers have been developing a state-of-the-art STORM proof checker, to name just 2 examples that directly fit into our four path classifications.
At SaferAI, we think more focused investment is needed but believe Europe should avoid picking a single winner in AI assurance. The field is still in early stages; it is unclear which paths will scale, and the most promising approaches each carry distinct benefits and trade-offs.
Direct neural network verification remains useful for narrower systems, but we do not expect it to scale to frontier AI for the reasons mentioned above. For the other three paths, we believe premature consolidation around any one would be a misstep. Instead, the EU’s strongest move would be to fund a diversified portfolio of high-risk, high-reward bets through a focused ARPA-style program.
Out of the three, we view honest predictors representing the most ambitious bet: they could potentially address the alignment problem at its root in creating AI systems that are safe from loss-of-control risk by design. However, scaling them up would require substantial investment, and much foundational work remains to be done.
World models in their full version seem to face similar challenges, but they carry a practical advantage: they can be deployed and piloted in narrower domains. For example, it is possible to model specific complex systems like telecommunications networks or power grids. As such, it would enable safer and more reliable AI sector by sector, building confidence before a broader rollout.
SPS is arguably the most tractable near-term option. The technology is closer to fruition than the other two, requiring less investment to deliver value. However, the gains are more bounded because SPS is set out to solve a smaller problem. Overall, its promise lies in improved societal resilience, resistance to cyber attacks in Europe, and potentially opening a credible path for AI deployment in Europe’s safety-critical industries, as the Inria–Mitsubishi Electric collaboration shows.
Focused funding is key
The previous considerations are why, in our position paper and joint declaration, we recommended an ARPA-style model for Europe to place these moonshot bets in reliability, safety, and security. The EU does not need to choose between these technologies yet, but it does need a focused structure and secured funding to develop them through to deployment.
Researchers are already working on these problems, but they are scattered across different NGOs and academia. What is missing is a program that brings them together, funds them seriously, and lets technical judgment decide how resources should shift as the evidence accumulates.
The UK’s ARIA is a good example of how this can work in practice. Its Safeguarded AI program and focused funding positioned the UK as a global center for this kind of work. The program started off focused on world models and recently pivoted more towards SPS. This shift demonstrates that even in a dedicated research organization, the choice of technology can evolve, following decisions by the scientists themselves, while the underlying policy strategy to safe-by-design AI holds firm.
The timing is promising because the EU is building the funding infrastructure that could support exactly this kind of focused research organization. The European Competitiveness Fund, the centerpiece of the EU’s proposed 2028–2034 budget, is meant to put tens of billions into strategic technologies through its Digital Leadership strand, which already covers AI, cybersecurity, and the AI Gigafactories. Earmarking even a small share for reliability, safety, and security research of the type discussed above would be more than sufficient to launch a serious program. The amounts involved are modest in context: our position paper estimates a foundational program could start at around €65 million a year (for one moonshot), which is a fraction of the hundreds of billions flowing into scaling AI.
In sum, Europe already has the talent and the early research. What is missing is the decision to bring them together in an efficient manner. As European leaders discuss the Union’s next budget, we call on them to seize the opportunity to build European leadership in reliable AI.
Thanks to Chloé Touzet and Alice Teilhard de Chardin for their comments on a draft of this post.


